
 R | Rstudio를 이용하지 않고 현재 파일이 있는 디렉토리 위치 불러오기
R | Rstudio를 이용하지 않고 현재 파일이 있는 디렉토리 위치 불러오기
R script를 실행할때 매번 Rstudio를 이용할 필요는 없다. 스크립트를 한줄한줄 확인하면서 실행할 필요가없다면 바로 Rscript로 실행하면 간편하다. 그렇다면 이런경우에는 어떻게 현재 디렉토리를 지정해줄 수 있을까? funr package의 get_script_path() function을 사용하면 된다. funr: Simple Utility Providing Terminal Access to all R Functions A small utility which wraps Rscript and provides access to all R functions from the shell. cran.r-project.org CURRENT_WORKING_DIR
R에서는 setwd()로 워킹디렉토리를 설정하고 설정된 워킹 디렉토리가 무엇인지 getwd()로 확인하는 작업을 해주어야한다. 그래야, 파일을 불러오거나 저장할때 그 위치를 알기고, 지정하기 쉽다. 이런점에서 python에서는 현재파일이 있는 위치가 자동으로 워킹 디렉토리로 설정이 되는 셈이였고, 그래서 절대경로와 상대경로 방법이 있었다. 하지만 R에서는 현재 파일이 있는 위치를 setwd()를 통해 지정해줘야, 절대와 상대경로 개념을 사용할 수 있게 된다. 그렇다면 현재 파일이 있는 위치는 어떻게 알아낼 수 있을까. 이런 방법이 있는지 몰랐을때 나는 하나씩 위치를 찾고 타이핑해서 지정 해줬었다. 이제는 안녕. C드라이브 Work 디렉토리 아래에 빈 test.R 파일을 하나 저장해두었다. 이 R 파일을 ..

 R | COVID-19 데이터로 무엇을 할 수 있을까 | 4. 확진자 증가 추세 추적 그래프
R | COVID-19 데이터로 무엇을 할 수 있을까 | 4. 확진자 증가 추세 추적 그래프
코로나19 상황에서 안정화에 진입한 국가는 어떤 국가가 있는지 알아보는 그래프를 그려보려고 합니다. 각 국가의 새로운 확진자의 수와 누적 확진자의 로그값을 이용하여 새로운 확진자가 감소하는, 즉 점차 안정화가 진행되는 국가는 어떤 국가가 있는지 알 수 있는 다음과 같은 그래프가 이번 포스팅의 목표입니다. # 이번 포스팅에서 완성하고자 하는 그래프 # 데이터 준비 > mydata_tb %>% dim [1] 19448 13 > mydata_tb$Country %>% + unique %>% + length [1] 187 > mydata_tb$Date %>% + max [1] "2020-05-04" 지난 포스팅과 같이 데이터를 다운받습니다. 2020-05-04 기준으로 187개 국가의 데이터가 받아졌습니다. >..
round()를 이용하면 반올림을 간단하게 해결 할 수 있습니다. 그 이외에도 R에는 올림과 내림을 간단히 할 수 있는 기본 함수가 있습니다. 우선 rnorm()을 이용해서 연습데이터를 생성해줍니다. 소숫점 아래 6자리까지 나오는 5개의 숫자를 생성했습니다. > numbers [1] -6.56710714 -0.09336418 -8.42598276 5.85306437 -2.28577976 ceiling()을 이용하면 올림을, > ceiling(numbers) [1] -6 0 -8 6 -2 floor()을 이용하면 내림을 할 수 있습니다. > floor(numbers) [1] -7 -1 -9 5 -3
소숫점 아래의 숫자를 반올림할때는 round()를 이용하면 간단하게 해결 할 수 있습니다. (올림과 내림을 하는 방법은 여기를 클릭) 우선 rnorm()을 이용해서 연습데이터를 생성해줍니다. 소숫점 아래 6자리까지 나오는 5개의 숫자를 생성했습니다. > numbers numbers [1] -1.848473 -7.264633 -9.627938 5.445361 1.999674 여기에서 round()를 기본으로 사용하면 소수부분이 모두 반올림되는것을 확인 할 수 있는데요, 거기에서 원하는 자릿수를 함께 입력해주면 반올림 위치가 변경되는것을 확인 할 수 있습니다. > round(numbers) [1] -2 -7 -10 5 2 > round(numbers,1) [1] -1.8 -7.3 -9.6 5.4 2.0 > ..
 R | COVID-19 데이터로 무엇을 할 수 있을까 | 2. 데이터 다운로드와 전처리
R | COVID-19 데이터로 무엇을 할 수 있을까 | 2. 데이터 다운로드와 전처리
지난 포스팅에서는 COVID-19가 무엇인지에대해서 적어보았는데요, 이번 포스팅에서는 데이터를 다운받고 준비하는 과정에 대해 이야기하려고합니다. 분석이나 시각화에 앞서 데이터를 손봐야하기 때문이죠 코로나19와 관련된 데이터는 다양한 기관에서 현재 제공을 해주고있습니다. 그중에서 저는 datahub의 covid-19 데이터를 받아서 사용을 했습니다. 데이터는 csv 파일의 다운로드 링크를 이용하면 R에서 바로 데이터를 받아 볼 수 있습니다. > mydata_raw mydata_raw %>% dim [1] 23496 8 > mydata_raw %>% head Date Country.Region Province.State Lat Long Confirmed Recovered Deaths 1 2020-01-22 ..
 R | COVID-19 데이터로 무엇을 할 수 있을까 | 1. 코로나바이러스감염증이란?
R | COVID-19 데이터로 무엇을 할 수 있을까 | 1. 코로나바이러스감염증이란?
# 코로나바이러스 감염증이란? 코로나바이러스 감염증-19(COVID-19)는 중증 극성 호흡기 증후군 코로나바이러스 2 (Severe Acute Respiratory Syndrome Coronavirus-2, SARS-CoV-2) 감염에 의한 호흡기 증후군을 뜻합니다. COVID-19의 의미는 Corona의 CO, Virus의 VI, Disease의 D, 처음 발병이 보고된 2019년도의 19를 의미하는데요, 우리나라에서는 이름을 줄여 코로나 19로 부르고 있습니다. (출처 질병관리본부) 코로나(corona)는 맥주의 이름으로 유명하지만 사실 코로나라는 이름은 다음 사진과 같이 일식이나 월식 때 해나 달 둘레에 생기는 광환을 말합니다. 코로나바이러스의 형태가 광환과 같이 구형을 이루고 있어서 코로나라는 ..
R에서는 비율을 구하는 방법이 여러가지 있는데요 그중에서도 matrix 테이블을 한번에 proportion 테이블로 변환시키는 작업을 많이 하게 됩니다. 이때 가장 편하게 사용하는게 prop.table() 함수입니다. # 연습용 데이터 셋 만들기 > mydata colnames(mydata) rownames(mydata) head(mydata) A B C sector-1 22 21 25 sector-2 81 32 39 sector-3 88 57 52 sector-4 86 8 46 sector-5 63 7 33 # prop.table(x) : sum() == 1 > prop.table(mydata) A B C sector-1 0.03333333 0.03181818 0.03787879 sector-2 0.1..
string을 다루는 데 사용하는 함수는 여러 가지가 있습니다. 그중에서 숫자에 반점을 찍는데 유용하게 사용할 수 있는 format() 함수의 사용방법을 연습해봤습니다. 다양한 R의 함수를 알고싶다면 > Handling strings with R 1. 원하는 자리수 마다 반점(comma) 찍기 > N format(N) [1] " 1" " 12345" "123456789" > format(N, big.mark = ',') [1] " 1" " 12,345" "123,456,789" > format(N, big.mark = ',', big.interval = 2) [1] " 1" " 1,23,45" "1,23,45,67,89" format() 함수가 좋은 점은 다음과 같이 원하는 자릿수마다 반점을 찍기에 유용..
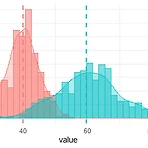 R | ggplot2로 히스토그램 그리기
R | ggplot2로 히스토그램 그리기
R의 기본 함수인 hist() 외에도 ggplot2를 이용해 더 정교한 히스토그램을 그릴 수 있습니다. hist()를 이용한 히스토그램 그리기가 궁금하다면 click > set.seed(1000) > df head(df) sample value 1 A 38 2 A 34 3 A 40 4 A 43 5 A 36 6 A 38 우선 A, B 두 샘플의 서로 다른 평균값을 가진 데이터를 만들어줍니다. > library(ggplot2) # Basic histogram > ggplot(df, aes(x=value)) + + geom_histogram() # Change the width of bins > ggplot(df, aes(x=value)) + + geom_histogram(binwidth=1) ggplot2 ..
자릿수가 큰 데이터를 출력할때 천단위로 콤마가 찍히도록 설정이 필요할 때가 있습니다. 세자리로 숫자를 나누고 그 사이에 콤마를 넣어주어도 되겠지만 R에는 이를 간편하게 할 수 있는 formattable 패키지가 있습니다. # install.packages('formattable') > library(formattable) 우선 formattable 패키지를 설치하고 라이브러리로 불러옵니다. > c(1250000, 225000, 123.456, 123.444) [1] 1250000.000 225000.000 123.456 123.444 벡터 형태의 숫자는 숫자 그래로 출력이 됩니다. > comma(c(1250000, 225000, 123.456, 123.444)) [1] 1,250,000.00 225,00..
 R | Correlation 그리는 세가지 방법 - pairs(), ggpairs(), corrplot()
R | Correlation 그리는 세가지 방법 - pairs(), ggpairs(), corrplot()
R에서 데이터의 상관관계를 확인하기위한 Correlation plot을 그리는 방법은 여러가지가 있습니다. 그중에서 pairs(), ggpairs(), corrplot() 세가지를 이용해서 correlation plot을 그려보도록 하겠습니다. 먼저 분석에 사용할 연습 데이터를 생성해줍니다. # make sample data -------------------------------------------------------- > set.seed(1000) > N sample_A % sort(decreasing = T) > sample_B sample_C data data %>% head sample_A sample_B sample_C 1 8.010215 5.929794 5.566053 2 7.862183..
 R | 히스토그램 그리기, hist()
R | 히스토그램 그리기, hist()
R을 이용하면 히스토그램을 간단하게 그려볼 수 있습니다. hist()명령어로 간단하게 그리는 방법에 대해 소개해볼께요. ggplot2를이용한 히스토그램 그리기가 궁금하다면 click 우선 간단한 숫자 리스트를 만들어줍니다. > data data [1] 35.37586 55.04595 51.39330 55.06370 40.92033 48.38859 43.78151 51.07321 [9] 58.02718 58.14942 43.89996 22.80327 41.42631 36.45985 21.86227 48.35124 [17] 42.38967 35.87544 44.24153 44.90620 45.36560 64.29275 48.81237 60.33052 [25] 56.08713 54.46291 64.46070 ..
 교육 | 통계청 통계교육원
교육 | 통계청 통계교육원
오늘은 통계청의 통계교육원에 대해서 소개를 하고 싶습니다. 이런 무료 강의가 있다고 누구도 알려주지 않더라고요. 통계교육원에서는 매달 오프라인 교육을 하는것은 물론이고, 이러닝으로 모든 사람들이 무료로 수업을 들을 수 있도록 제공해주고있습니다. 오프라인 교육의 경우 공무원분들이 승진과 관련하여 여러 수업을 이수해야 하는 기준이 있는것으로 알고 있는데요(저는 공무원이 아니라서 자세히는 모릅니다) 하지만 이 수업이 공무원에게만 열려있는것은 아닙니다. 그래서 통계업무와 관련일을 하고 계신 분이라면 한번 강의를 확인해보시는걸 추천해드려요. * 코로나 19로 인해 대부분의 집합 교육과정도 취소된것 같네요. 모두들 계신곳에서 안전하시길 바랍니다. 2020년 수강이 가능한 온라인 강의 목록을 아래 적어두었는데요. 수..
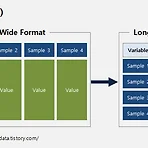 R | reshape2의 melt를 이용한 데이터 재구조화
R | reshape2의 melt를 이용한 데이터 재구조화
reshape2 cast Long Format to Wide Format melt Wide Format to Long Format 옆으로 길게 나열되어있는(wide format) 데이터를 아래로 길게 이어는(long format) 데이터로 바꿔주는 melt 함수의 사용법에 대해 보겠습니다. 우선 reshape2 패키지를 설치하고 불러와주세요. > install.packages(reshape2) > library(reshape2) 그리고 연습에 이용할 간단한 데이터를 만들어주었습니다. 간단한 데이터 셋을 이용해 전체적인 큰 틀을 이해하고 나면, 그 다음에 R에서 제공해주는 다양한 데이터 셋에 적용해 연습해보시기 바랍니다. > section year sample_1 sample_2 sample_3 sampl..
 R | reshape2의 cast()를 이용한 데이터 재구조화
R | reshape2의 cast()를 이용한 데이터 재구조화
분석을 하다 보면 데이터 셋의 재구조화 작업을 수도 없이 해야 합니다. 이때 꼭 알고 있어야 하는 reshape 패키지의 cast() 함수에 대해 살펴보겠습니다. 분석에 사용할 reshape 패키지를 다운받고 라이브러리를 불러옵니다. install.packages(reshape2) library(reshape2) 우선 데이터 셋을 만듭니다. 4가지 섹션에 A, B 두 샘플의 값으로 간단하게 만들었습니다. > section sample value data data section sample value 1 section-1 A 5 2 section-2 A -1 3 section-3 A -15 4 section-4 A -2 5 section-1 B 9 6 section-2 B -2 7 section-3 B -..
 R | 연결된 선이 있는 Bar Plot 그리기(2 samples)
R | 연결된 선이 있는 Bar Plot 그리기(2 samples)
R에서 연결된 선이 있는 Bar Plot을 그리는 방법이 있다는 점에 놀라 이 포스팅을 클릭하셨나요? 사실 R에서 연결된 선이 있는 Bar Plot을 그리는 기능은 없습니다. 어떻게 아냐고요? 저도 알고 싶지 않았습니다. 혹시 알고 계신 분이 있다면 댓글을 달아주세요. 그런 의미에서 저는 약간의 트릭을 사용한 방법을 공유하고자 합니다. 중요한 점은 제가 원하는 그래프를 얻었다는 것이겠죠. 우선 필요한 라이브러리를 불러옵니다. library(dplyr) library(ggplot2) library(reshape) dataset을 만들어줍니다. > sample category % + factor(level=c("level 1" , "level 2" , "level 3", "level 4")) > value ..
 R | 동일한 데이터로 8가지 기본 그래프 그리기 (ggplot)
R | 동일한 데이터로 8가지 기본 그래프 그리기 (ggplot)
하나의 데이터도 전달하는 자의 의도에 따라 다양한 그래프로 표현이 가능합니다. 그래서 어떤 그래프 형태를 이용해야 더 효과적으로 의미를 전달할 수 있을까 항상 고민을 하게 되는것 같습니다. 간혹 인터넷에서 통계자료를 보면서 기발한 아이디어를 얻기도 하고, 때로는 저 그래프보다는 다른 형식이 더 좋았을텐데 하고 아쉬움이 들기도 합니다. 그럼 R의 강력한 visualizing 패키지인 ggplot을 이용해서 기본 8가지 그래프 그리기를 해보겠습니다. [ ggplot ] 1. geom_bar() 2. geom_area() 3. geom_line() 4. geom_point() 우선 이번에 사용할 라이브러리를 불러옵니다. library(viridis) library(ggplot2) library(dplyr) 연..
 R | aggregation을 이용해 그룹별 데이터 합하기
R | aggregation을 이용해 그룹별 데이터 합하기
큰 데이터를 다루다보면 그룹별 합을 해야하는 경우가 많습니다. 엑셀의 SUMIF 기능이라고 생각하면 간단한데요 R에서 더욱 편리하게 적용할 수 있습니다. 연습 데이터를 다음과 같이 만들었습니다 > v1 v2 v3 v123 v123 v1 v2 v3 1 A 2020 100 2 A 2019 500 3 A 2020 400 4 A 2019 300 5 B 2019 250 6 B 2020 80 7 B 2019 400 8 B 2019 200 이 데이터에서 A와 B의 합을 다음과 같이 구할 수 있습니다. by=list(v123$v1) 를 이용했기 때문에 Group.1 에 A와 B의 값이 들어가 있는것을 볼 수 있습니다. > aggregate(v123$v3, by=list(v123$v1), FUN=sum) Group.1 ..
- Total
- Today
- Yesterday
- coronavirus
- SEQ
- plot
- 데이터
- 숫자
- Python
- 팟빵
- comma
- format
- BIOINFORMATICS
- for loop
- RStudio
- Cast
- 파이썬
- 2진수
- geom_line
- covid
- Excel
- Coding
- data
- r
- visualizing
- Visualization
- geom_bar
- Heatmap
- Command
- hist
- Order
- 엑셀
- 코로나바이러스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |