
 R | Clustering된 Heatmap 그리기, pheatmap,
R | Clustering된 Heatmap 그리기, pheatmap,
pheatmap을 이용해서 clustering된 heatmap을 그리는 방법 (본 포스팅에 사용된 데이터 셋은 위 링크를 통해 받을 수 있습니다.) # 목표 히트맵 1. Importing Test Data > myData myData %>% dim [1] 15 15 > myData %>% head A B C D E F G H I J K L M N O A 100.0 79.7 79.8 80.6 80.4 80.9 80.0 79.9 79.1 94.6 79.7 94.7 95.0 95.0 78.8 B 79.7 100.0 84.8 84.7 84.3 86.0 92.0 85.3 83.6 80.3 85.0 79.8 79.8 78.7 85.3 C 79.8 84.8 100.0 88.9 90.7 90.9 84.7 88.8 85..
 R | 꼭 알아야할 RStudio기능, 스크립트 빠르게 수정하기, (Crtl + F)
R | 꼭 알아야할 RStudio기능, 스크립트 빠르게 수정하기, (Crtl + F)
스크립트를 작성하다보면 지정해둔 특정 변수 이름을 바꿔야하는 경우가 종종 발생합니다. 하지만 이때 해당 문자를 일일히 찾아가며 수정하기에는 시간도 들고, 우리의 눈도 정확하지 않을 수 있겠죠. 이럴때 한번에 여러 글자를 바꿔주는 방법이 있습니다. 바로 Ctrl + F 입니다. 이는 특정 단어를 찾아주는 기능인데요, Rstudio에서 All 버튼을 이용하면 특별한 기능이 됩니다. Ctrl + F 를 누르게되면 Find 할 단어를 입력할 수 있습니다. 입력후 오른쪽에 있는 All 버튼을 클릭하게 되면 스크립트 내 해당되는 모든 단어를 인식하게 되는데요 이때 원하는 단어를 입력해서 어느 위치에있는 단어가 어떻게 바뀌는지 실시간으로 확인이 가능합니다. 물론 오른쪽의 Replace 란에 입력을 하고 그 오른편의 ..
분석을 하면서 for loop을 안써봤다고 하면 거짓말이겠죠. 오늘은 for loop 을 사용면서 쉽게 간과했을법한 문제에 대해 포스팅해보려고 합니다. 바로 빈 벡터로 인한 문제입니다. 반복문을 사용하기위해 벡터를 입력해주었는데 이게 빈 벡터일 경우 우리가 생각치 못한 문제가 발생할 수 있습니다. 우선 다음의 벡터를 이용해 우리가 알고있는 반복문을 실행해보았습니다. 여러개의 요소가 들어있는 벡터x를 이용해서 벡터의 길이만큼 반복 실행을 하려고 한다면 쉽게 사용할 수 있는 방법이 for (i in seq(length(x)) 혹은 for(i in 1:length(x))입니다. 실제로 저도 이런 방식으로 많은 분석을 했었고요. 그리고 다음 예시와 같이 문제없이 실행이 됩니다. > NotEmptyVector f..
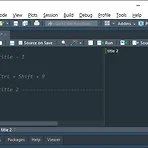 R | 알아두면 좋은 Rstudio 기능, 잘 정리된 스크립트를 짜는 방법, Crtl+Shift+R
R | 알아두면 좋은 Rstudio 기능, 잘 정리된 스크립트를 짜는 방법, Crtl+Shift+R
오늘은 R studio를 이용해서 R script를 짤때 알아두면 좋은 기능을 하나 알려드리려 합니다. 이 기능을 알기 이전의 저는 스크립트를 짤때면 다음과 같이 섹션의 제목을 적고 시작했는데요, 주석기능을 이용한것입니다. 하지만 특별할건 없죠 새로운 섹션을 시작할 위치에서 Ctrl + Shift + R 을 동시에 눌러주세요. 그러면 다음과 같이 Insert Section창이 나옵니다. 그럼 이곳에 원하는 섹션 이름을 입력해주세요. 저는 'title 2' 라고 입력해보겠습니다. TaDa! 자동으로 깔끔하게 섹션이 나눠지는 아름다운 장면입니다. 화살표로 가리킨 삼각탭을 누르면 해당 섹션을 접을수도 있고, 아래를 보면 현재 어느 섹션에서 작업중인지도 알 수 있습니다. 게다가 우측 상단의 글 탭을 눌러보면 나..
분석을 하다보면 샘플 이름을 이용해서 리스트를 만들어야 하는경우가 많습니다. 그럴때마다 직접 한땀 한땀 자판을 두들겨 이름을 설정해도 되지만 R 을 사용하면 그럴 필요가 없겠죠. seq(), rep(), paste() 정도면 대부분의 샘플 이름은 간단히 만들 수 있습니다. # seq() > seq(1,10) [1] 1 2 3 4 5 6 7 8 9 10 # rep() > rep('A',5) [1] "A" "A" "A" "A" "A" # paste() > paste('A',c(1,2,3), sep = ' ') [1] "A 1" "A 2" "A 3" # 반복샘플의 이름 A, B, C 총 세개의 샘플에 대해서, 한 샘플당 다섯번씩 반복해서 실험을 한다면 다음과 같이 만들 수 있습니다. > repeat_no re..
데이터를 분석하다 보면, 데이터 정렬을 자주 해야합니다. 그럴때 R에서는 order(), sort() 기능을 이용해 간편하게 오름차순과 내림차순으로 데이터를 정렬할 수 있는데요 이 두 기능이 가져오는 결과는 조금 다릅니다. 우선 데이터 셋을 만들어줍니다. > v1 v2 v3 v123 v123 v1 v2 v3 1 Apple 1 1000 2 Orange 2 2000 3 Apple 3 2000 4 Orange 3 1000 5 Apple 2 3000 6 Orange 1 3000 7 Apple 1 2000 과일별 갯수와 가격을 나타내는 데이터를 이용해 가격을 정렬해서 가격이 어떻게 분포하는지를 확인하려 한다면 sort()를 사용해보자. # sort( ) sort(x, decreasing = F) 를 이용해서 간단..
어떤 작업을 시작할때 해당 폴더를 직접 들어가서 새폴더를 생성하고, 이름을 수정해주고 작업을 진행 할 수 도 있습니다. 하지만 어느날 분석 데이터의 양이 많아지면서 폴더도 100개씩 만들어야 하는 경우가 생긴다면? 더 나아가 100개 폴더를 만드는 과정을 반복해야 한다면? 하나씩 직접 만들기에는 우리의 시간이 너무 아깝겠지요. R을 이용해서 빠르게 해봅시다. 먼저 워킹디렉토리를 설정합니다. > setwd("C:/chloe-with-data") > getwd() [1] "C:/chloe-with-data" # 디렉토리 생성 > dir.create('new_directory’) # 파일 생성 > file.create('new_text_file.txt') # 디렉토리 100개 만들기 하나씩 만드는것 쯤이야 쉽..
- Total
- Today
- Yesterday
- covid
- for loop
- Order
- comma
- data
- Heatmap
- Cast
- SEQ
- plot
- Command
- 데이터
- RStudio
- 파이썬
- 숫자
- 팟빵
- 2진수
- 코로나바이러스
- geom_bar
- coronavirus
- Excel
- r
- 엑셀
- Coding
- BIOINFORMATICS
- hist
- Visualization
- visualizing
- format
- geom_line
- Python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |