
Trim Galore는 fastaq 리드 파일에서 adapter trimming과 quality trimming 할 수 있는 편리한 프로그램입니다. adapter trimming 기능을 이용해서 polyA 서열 또한 제거를 할 수 있는데요, 옵션은 다음과 같습니다. -a/--adapter Adapter sequence to be trimmed. If not specified explicitly, Trim Galore will try to auto-detect whether the Illumina universal, Nextera transposase or Illumina small RNA adapter sequence was used. Also see --illumina, --nextera and --s..
 R | COVID-19 데이터로 무엇을 할 수 있을까 | 1. 코로나바이러스감염증이란?
R | COVID-19 데이터로 무엇을 할 수 있을까 | 1. 코로나바이러스감염증이란?
# 코로나바이러스 감염증이란? 코로나바이러스 감염증-19(COVID-19)는 중증 극성 호흡기 증후군 코로나바이러스 2 (Severe Acute Respiratory Syndrome Coronavirus-2, SARS-CoV-2) 감염에 의한 호흡기 증후군을 뜻합니다. COVID-19의 의미는 Corona의 CO, Virus의 VI, Disease의 D, 처음 발병이 보고된 2019년도의 19를 의미하는데요, 우리나라에서는 이름을 줄여 코로나 19로 부르고 있습니다. (출처 질병관리본부) 코로나(corona)는 맥주의 이름으로 유명하지만 사실 코로나라는 이름은 다음 사진과 같이 일식이나 월식 때 해나 달 둘레에 생기는 광환을 말합니다. 코로나바이러스의 형태가 광환과 같이 구형을 이루고 있어서 코로나라는 ..
R에서는 비율을 구하는 방법이 여러가지 있는데요 그중에서도 matrix 테이블을 한번에 proportion 테이블로 변환시키는 작업을 많이 하게 됩니다. 이때 가장 편하게 사용하는게 prop.table() 함수입니다. # 연습용 데이터 셋 만들기 > mydata colnames(mydata) rownames(mydata) head(mydata) A B C sector-1 22 21 25 sector-2 81 32 39 sector-3 88 57 52 sector-4 86 8 46 sector-5 63 7 33 # prop.table(x) : sum() == 1 > prop.table(mydata) A B C sector-1 0.03333333 0.03181818 0.03787879 sector-2 0.1..
string을 다루는 데 사용하는 함수는 여러 가지가 있습니다. 그중에서 숫자에 반점을 찍는데 유용하게 사용할 수 있는 format() 함수의 사용방법을 연습해봤습니다. 다양한 R의 함수를 알고싶다면 > Handling strings with R 1. 원하는 자리수 마다 반점(comma) 찍기 > N format(N) [1] " 1" " 12345" "123456789" > format(N, big.mark = ',') [1] " 1" " 12,345" "123,456,789" > format(N, big.mark = ',', big.interval = 2) [1] " 1" " 1,23,45" "1,23,45,67,89" format() 함수가 좋은 점은 다음과 같이 원하는 자릿수마다 반점을 찍기에 유용..
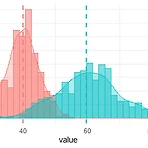 R | ggplot2로 히스토그램 그리기
R | ggplot2로 히스토그램 그리기
R의 기본 함수인 hist() 외에도 ggplot2를 이용해 더 정교한 히스토그램을 그릴 수 있습니다. hist()를 이용한 히스토그램 그리기가 궁금하다면 click > set.seed(1000) > df head(df) sample value 1 A 38 2 A 34 3 A 40 4 A 43 5 A 36 6 A 38 우선 A, B 두 샘플의 서로 다른 평균값을 가진 데이터를 만들어줍니다. > library(ggplot2) # Basic histogram > ggplot(df, aes(x=value)) + + geom_histogram() # Change the width of bins > ggplot(df, aes(x=value)) + + geom_histogram(binwidth=1) ggplot2 ..
자릿수가 큰 데이터를 출력할때 천단위로 콤마가 찍히도록 설정이 필요할 때가 있습니다. 세자리로 숫자를 나누고 그 사이에 콤마를 넣어주어도 되겠지만 R에는 이를 간편하게 할 수 있는 formattable 패키지가 있습니다. # install.packages('formattable') > library(formattable) 우선 formattable 패키지를 설치하고 라이브러리로 불러옵니다. > c(1250000, 225000, 123.456, 123.444) [1] 1250000.000 225000.000 123.456 123.444 벡터 형태의 숫자는 숫자 그래로 출력이 됩니다. > comma(c(1250000, 225000, 123.456, 123.444)) [1] 1,250,000.00 225,00..
 R | Correlation 그리는 세가지 방법 - pairs(), ggpairs(), corrplot()
R | Correlation 그리는 세가지 방법 - pairs(), ggpairs(), corrplot()
R에서 데이터의 상관관계를 확인하기위한 Correlation plot을 그리는 방법은 여러가지가 있습니다. 그중에서 pairs(), ggpairs(), corrplot() 세가지를 이용해서 correlation plot을 그려보도록 하겠습니다. 먼저 분석에 사용할 연습 데이터를 생성해줍니다. # make sample data -------------------------------------------------------- > set.seed(1000) > N sample_A % sort(decreasing = T) > sample_B sample_C data data %>% head sample_A sample_B sample_C 1 8.010215 5.929794 5.566053 2 7.862183..
 검색어 트렌드 | 구글 트렌드, 네이버 데이터랩
검색어 트렌드 | 구글 트렌드, 네이버 데이터랩
온라인상의 검색어 트렌드는 생각 이상으로 많은 정보를 담고 있습니다. 처음 구글 트렌드 서비스를 알게 된 때는 트럼프와 힐러리가 대선 후보로 경쟁을 하던 때였는데요. 그때 당시 두 후보에 대한 검색어 비율을 기반으로 누가 당선이 될지 예측을 해보기도 했었습니다. 사람들 사이에서 어떤 새로운 트렌드가 생성되면 그 검색량이 어떻게 변하는지 궁금해서 가끔씩 검색을 해보게 되는 것 같습니다. 이번에도 코로나바이러스와 관련한 검색어가 어떻게 구성되어있을지 궁금해서 구글 트렌드로 확인해봤습니다. 검색지역은 한국으로 설정을 하였고, 최근 3개월의 데이터로 제한했습니다. 1. Corona 2. COVID 3. 코로나 4. 마스크 위의 결과를 보면 역시나 한글 검색어인 코로나가 가장 많은 높은 검색량을 보였습니다. 그리..

 Linux | Handbook 웹사이트
Linux | Handbook 웹사이트
Linux Handbook Linux Command Line, Server, DevOps and Cloud linuxhandbook.com Linux command 사용법은 물론, Linux Terminal 관련 팁과 더 자세한 사용법까지, 다양한 리눅스 활용법을 제공하고 있습니다. 리눅스 환경을 사용해야 하는데 아직 익숙지 않은 분들은 이 웹사이트의 튜토리얼을 따라 해 보면서 연습하기 좋고, 이미 리눅스 코멘드를 사용할 줄 알더라도, 더 많은 팁을 얻어 갈 수 있을 것 같습니다. Linux Handbook을 통해 리눅스 천재의 길로 한걸음 다가서는데 도움이 되길 바랍니다.
오늘은 김혜리의 필름클럽을 소개해 볼까 하는데요. 이 팟캐스트는 이미 많은 분들이 듣고계시지 않을까 생각됩니다. 김혜리의 필름클럽에서는 김혜리 기자와 임수정 배우, 최다은 피디가 함께 영화를 이야기합니다. 영화 기자와 배우와 음악 전문 피디님까지 함께 모이니 하나의 영화에 대해서도 정말 다양한 이야기를 함께 나누어주십니다. 영화 이야기를 다루는 다른 많은 팟캐스트와 방송들이 있지만, 그중에 제일이라고 할 수 있겠는데요. 잔잔한 분위기가 특징적이어서 평소에 배경음으로도 자주 틀어두기도 합니다. 필름 클럽이 여러분의 영화 문화생활에 많은 도움이 되길 바랍니다. 팟캐스트 김혜리의 필름클럽 방송듣기, : 팟빵 김혜리의 필름클럽 : 씨네21 김혜리 기자, SBS 최다은 PD, 배우 임수정이 영화와 음악을 이야기합..
 R | 히스토그램 그리기, hist()
R | 히스토그램 그리기, hist()
R을 이용하면 히스토그램을 간단하게 그려볼 수 있습니다. hist()명령어로 간단하게 그리는 방법에 대해 소개해볼께요. ggplot2를이용한 히스토그램 그리기가 궁금하다면 click 우선 간단한 숫자 리스트를 만들어줍니다. > data data [1] 35.37586 55.04595 51.39330 55.06370 40.92033 48.38859 43.78151 51.07321 [9] 58.02718 58.14942 43.89996 22.80327 41.42631 36.45985 21.86227 48.35124 [17] 42.38967 35.87544 44.24153 44.90620 45.36560 64.29275 48.81237 60.33052 [25] 56.08713 54.46291 64.46070 ..
 팟캐스트 추천 2탄 | 언니들의 슬기로운 조직생활, 언슬조
팟캐스트 추천 2탄 | 언니들의 슬기로운 조직생활, 언슬조
직장생활을 하는 분들은 물론, 프리랜서, 학생, N잡러, 육아휴직 중인 분들까지 모두 구독하고 있어야 할 팟캐스트 언슬조를 소개합니다. 팟캐스트 언니들의 슬기로운 조직생활 (언슬조): 전우주 직장인 팟캐 방송듣기, : 팟빵 언니들의 슬기로운 조직생활 (언슬조): 전우주 직장인 팟캐 : 여자 직장인들이 한자리에 모였다! 부장, 차장, 과장, 대리, 사원까지 5명의 여성 직장인이 모여 펼치는 절대수다의 향연. 지금 팟빵 모바일앱에서 방송을 들으면 캐시를 적립해드립니다. www.podbbang.com 언슬조는 언니들의 슬기로운 조직생활의 줄임말인데요. 부장, 차장, 과장, 대리, 사원까지 여러 여성 직장인이 모여서 서로의 조직생활에 대해 모든 것을 이야기합니다. 2018년 초기에 이 팟캐스트가 시작해서 벌써 ..
 교육 | 통계청 통계교육원
교육 | 통계청 통계교육원
오늘은 통계청의 통계교육원에 대해서 소개를 하고 싶습니다. 이런 무료 강의가 있다고 누구도 알려주지 않더라고요. 통계교육원에서는 매달 오프라인 교육을 하는것은 물론이고, 이러닝으로 모든 사람들이 무료로 수업을 들을 수 있도록 제공해주고있습니다. 오프라인 교육의 경우 공무원분들이 승진과 관련하여 여러 수업을 이수해야 하는 기준이 있는것으로 알고 있는데요(저는 공무원이 아니라서 자세히는 모릅니다) 하지만 이 수업이 공무원에게만 열려있는것은 아닙니다. 그래서 통계업무와 관련일을 하고 계신 분이라면 한번 강의를 확인해보시는걸 추천해드려요. * 코로나 19로 인해 대부분의 집합 교육과정도 취소된것 같네요. 모두들 계신곳에서 안전하시길 바랍니다. 2020년 수강이 가능한 온라인 강의 목록을 아래 적어두었는데요. 수..
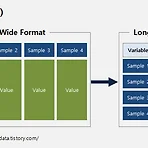 R | reshape2의 melt를 이용한 데이터 재구조화
R | reshape2의 melt를 이용한 데이터 재구조화
reshape2 cast Long Format to Wide Format melt Wide Format to Long Format 옆으로 길게 나열되어있는(wide format) 데이터를 아래로 길게 이어는(long format) 데이터로 바꿔주는 melt 함수의 사용법에 대해 보겠습니다. 우선 reshape2 패키지를 설치하고 불러와주세요. > install.packages(reshape2) > library(reshape2) 그리고 연습에 이용할 간단한 데이터를 만들어주었습니다. 간단한 데이터 셋을 이용해 전체적인 큰 틀을 이해하고 나면, 그 다음에 R에서 제공해주는 다양한 데이터 셋에 적용해 연습해보시기 바랍니다. > section year sample_1 sample_2 sample_3 sampl..
 Bioinformatics tool | EMBOSS Seqret (Sequence Format Conversion), abi파일을 fastq와 fasta로, fastq파일을 fasta로 변환하기
Bioinformatics tool | EMBOSS Seqret (Sequence Format Conversion), abi파일을 fastq와 fasta로, fastq파일을 fasta로 변환하기
EMBOSS 프로그램은 sequence analysis를 위한 다양한 툴을 제공하고있습니다. 그중에서 Sequence Format Conversion기능의 seqret으로 fastq 파일을 fasta로 변환하는 방법에 대해 소개하려합니다. 우선 EMBOSS 프로그램이 없으면 아래 링크를 통해 다운로드를 받아주세요. 다운로드 후에는 압축을 풀면 특별한 설치 과정없이 바로 사용이 가능합니다. EMBOSS Downloads EMBOSS Downloads Contents The EMBOSS package is available from our new FTP server ftp://emboss.open-bio.org/pub/EMBOSS/ in the file EMBOSS-6.5.7.tar.gz This distr..
 R | reshape2의 cast()를 이용한 데이터 재구조화
R | reshape2의 cast()를 이용한 데이터 재구조화
분석을 하다 보면 데이터 셋의 재구조화 작업을 수도 없이 해야 합니다. 이때 꼭 알고 있어야 하는 reshape 패키지의 cast() 함수에 대해 살펴보겠습니다. 분석에 사용할 reshape 패키지를 다운받고 라이브러리를 불러옵니다. install.packages(reshape2) library(reshape2) 우선 데이터 셋을 만듭니다. 4가지 섹션에 A, B 두 샘플의 값으로 간단하게 만들었습니다. > section sample value data data section sample value 1 section-1 A 5 2 section-2 A -1 3 section-3 A -15 4 section-4 A -2 5 section-1 B 9 6 section-2 B -2 7 section-3 B -..
 R | 연결된 선이 있는 Bar Plot 그리기(2 samples)
R | 연결된 선이 있는 Bar Plot 그리기(2 samples)
R에서 연결된 선이 있는 Bar Plot을 그리는 방법이 있다는 점에 놀라 이 포스팅을 클릭하셨나요? 사실 R에서 연결된 선이 있는 Bar Plot을 그리는 기능은 없습니다. 어떻게 아냐고요? 저도 알고 싶지 않았습니다. 혹시 알고 계신 분이 있다면 댓글을 달아주세요. 그런 의미에서 저는 약간의 트릭을 사용한 방법을 공유하고자 합니다. 중요한 점은 제가 원하는 그래프를 얻었다는 것이겠죠. 우선 필요한 라이브러리를 불러옵니다. library(dplyr) library(ggplot2) library(reshape) dataset을 만들어줍니다. > sample category % + factor(level=c("level 1" , "level 2" , "level 3", "level 4")) > value ..
 R | 동일한 데이터로 8가지 기본 그래프 그리기 (ggplot)
R | 동일한 데이터로 8가지 기본 그래프 그리기 (ggplot)
하나의 데이터도 전달하는 자의 의도에 따라 다양한 그래프로 표현이 가능합니다. 그래서 어떤 그래프 형태를 이용해야 더 효과적으로 의미를 전달할 수 있을까 항상 고민을 하게 되는것 같습니다. 간혹 인터넷에서 통계자료를 보면서 기발한 아이디어를 얻기도 하고, 때로는 저 그래프보다는 다른 형식이 더 좋았을텐데 하고 아쉬움이 들기도 합니다. 그럼 R의 강력한 visualizing 패키지인 ggplot을 이용해서 기본 8가지 그래프 그리기를 해보겠습니다. [ ggplot ] 1. geom_bar() 2. geom_area() 3. geom_line() 4. geom_point() 우선 이번에 사용할 라이브러리를 불러옵니다. library(viridis) library(ggplot2) library(dplyr) 연..
 R | aggregation을 이용해 그룹별 데이터 합하기
R | aggregation을 이용해 그룹별 데이터 합하기
큰 데이터를 다루다보면 그룹별 합을 해야하는 경우가 많습니다. 엑셀의 SUMIF 기능이라고 생각하면 간단한데요 R에서 더욱 편리하게 적용할 수 있습니다. 연습 데이터를 다음과 같이 만들었습니다 > v1 v2 v3 v123 v123 v1 v2 v3 1 A 2020 100 2 A 2019 500 3 A 2020 400 4 A 2019 300 5 B 2019 250 6 B 2020 80 7 B 2019 400 8 B 2019 200 이 데이터에서 A와 B의 합을 다음과 같이 구할 수 있습니다. by=list(v123$v1) 를 이용했기 때문에 Group.1 에 A와 B의 값이 들어가 있는것을 볼 수 있습니다. > aggregate(v123$v3, by=list(v123$v1), FUN=sum) Group.1 ..
- Total
- Today
- Yesterday
- Heatmap
- visualizing
- Coding
- data
- 숫자
- comma
- Excel
- covid
- for loop
- Cast
- hist
- RStudio
- 2진수
- 엑셀
- r
- Visualization
- format
- coronavirus
- SEQ
- Command
- 파이썬
- BIOINFORMATICS
- geom_line
- Order
- 팟빵
- plot
- 코로나바이러스
- Python
- 데이터
- geom_bar
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |